Urban Sound Processing and Neural Network Model
Data exploration
The dataset we want to analyze consists of different soundbites each of length 1 second containing the highest intensity in a larger soundbite. The dataset has sounds such as a dog barking, children playing, car horn, and streetmusic. Lets have a look and see how the different kinds of sounds look like in comparison to one another.
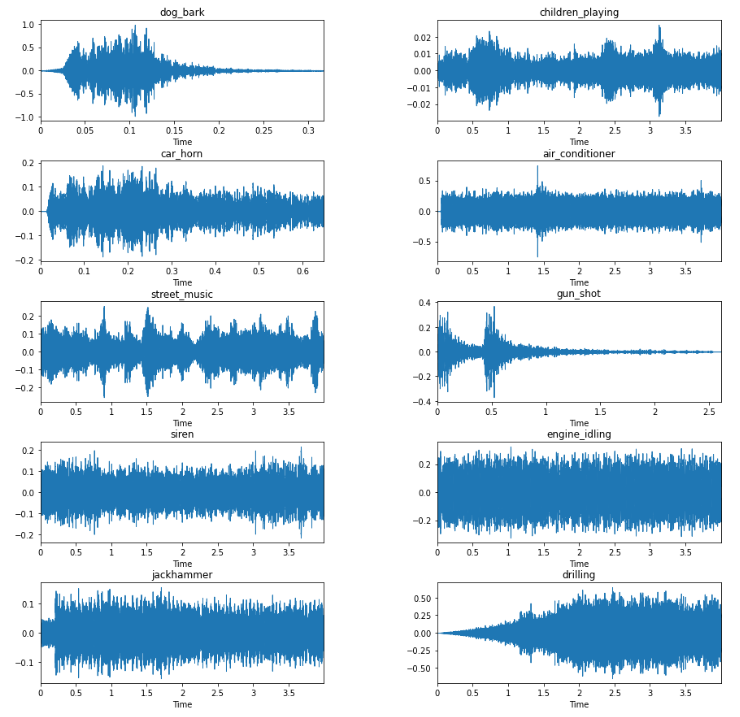
Feature extraction
The features we will use to analyze the difference in these soundbites will be the Mel-frequency cepstral coefficients (MFCCs). We will use 40 coefficients to describe our sound bite. The librosa library will be used to apply the functions nessesary to get to this representation of the features.
The process to arrive at the MFCCs are.
Taking the Fourier transform
Map the powers of the spectrum to the mel scale
Take the log of the powers
Take the discrete cos transform
Out we will get the amplitudes of the spectrum
The MFCC are useful for sound classification as they resemble the human spectrum. In short it has a higher destrinction between sounds of powered amplitudes and frequencies. Humans usually experience sounds in a radical way, as to say that a linear increase in sound amplitude will by a human be interpreted of a much higher degree. The MFCCs contains the information for the soundbites, we will use these later.
Preparing data for training
For easier processing of the data we will shift and normalize the data. Shifting the data close to 0 and normalizing them approximately close from -1 to 1, makes computations faster.
The labels, or the predetermined category that the sound lies in, will be encoded into a vector of length number of different sounds. The model will then try to determine which of these categories the sound lies in with a probablity. The softmax activation layer will then return the highest probability as the label that is most probable to be true.
Neural Network model
We will train the data on a neural network model with dense layers and RELU activation layers. The input shape will be all of our train datapoints with each 40 features. The output will be of the shape of the number of labels that we have, 10.
For training the model we will use a validation set, that evaluates the weights of the model after each epoch. The weights are updated according to how they best influence the validation datapoints in a direction that gives a higher accuracy.
num_labels = yy.shape[1]
def build_model_graph(input_shape=(n_mfcc,)):
model = Sequential()
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
# Compile the model
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
return model
model = build_model_graph()Evaluating the model process
After training the model with a batchsize of 256 (the number of datapoints that are each clumbed together with each epoch at random) on 1000 epochs, we have the following development of our loss and accuracy on the validation and the training set.
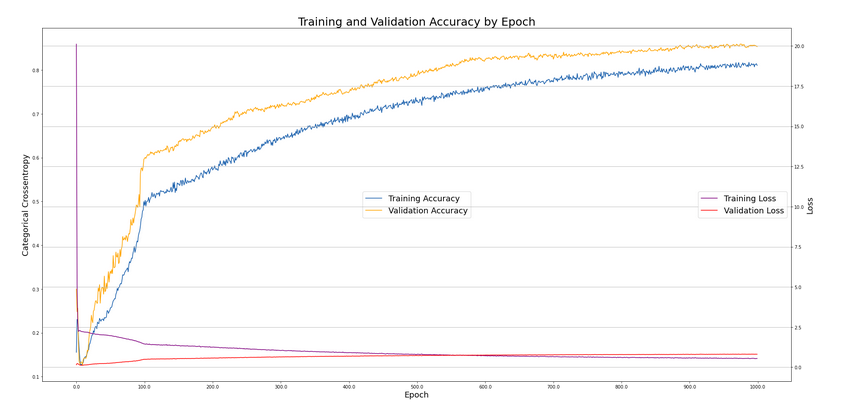
We can see that the accuracy of the training set is about 10 percentage points higher that the validation accuracy, the loss is falling for the training set, but it is starting to increase for the validation set. The model can still be trained, as we have not seen a convergence in the accuracy yet. A danger will be that we overfit the model to the training set, and thus can expect lower accuracy on test data.
Lets try to see how high our testing set fares with the model that we have created.

As we saw in the plot above the training accuracy is at ~91%, while the testing accuracy is ~84%.
Looking at the wrongly predicted sound bites
Below we have a table of the predicted sounds from the model, and the predetermined labels given to the sound bites. We can see that children_playing is predicted far too often for the model. It classifies this category mainly for sounds that are dog_bark, gun_shot, and street_music. Two of them might have some correlation, but the fact that the model classifies a gun_shot as children_playing can have obvious implications if this model were to be released into a real world application.
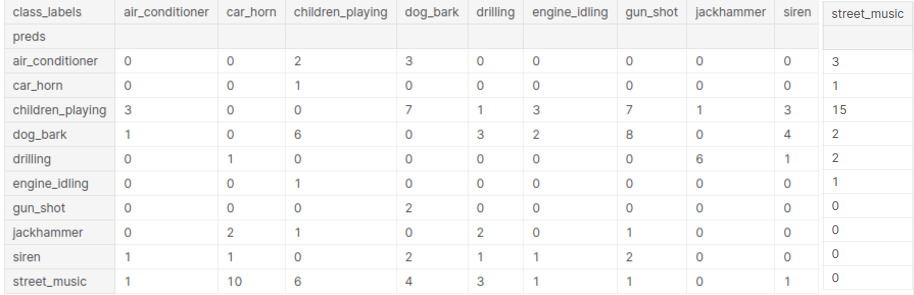
We can play the sounds to hear for ourselves, and try to find an explanation for why the model predicted as it did.
To have a closer look at all the sound bites that the model predicted wrong have a look at the kaggle.
We use the following code to run through all the sound bites.
#Play a sound from the dataset
sound_file = '/kaggle/input/urbansounds/UrbanSound8K/audio/'
for index, row in df_unequal.iterrows():
slice_name = row['file_name']
name= sound_file+slice_name
print("Name of file: {} , Predicted to be: {} , Real Value: {} ".format(slice_name , row['preds'] ,row['class_labels']))
input(ipd.display(ipd.Audio(name,autoplay=True)))
clear_output(wait=True)The below sound bite is an example from which I think the model actually does a better job than who classified the sound bite in the dataset.
One instance in particular, where the sound is prelabeled to be a car_horn, and predicted to be a jackhammer. But the car_horn is in the background, and the jackhammer is in the foreground. So I think the classifier actually does a better job here than the human person who classified the sound bite.
Audio('/kaggle/input/urbansounds/UrbanSound8K/audio/fold4/7389-1-0-4.wav')
The sound bite below is an example of a sound bite that doesnt really classifies as any of the sound labels. The soundbite is just noise, and this should probably be emitted from the dataset.
Audio('/kaggle/input/urbansounds/UrbanSound8K/audio/fold4/194458-9-1-75.wav')
Some sound bites are so low in amplitude that is not possible to distinguish what the sound actually is. These sound bites should also be emitted from the dataset.
In conclusion
The model actually does a fairly well job, and eventhough it not able to classify all sound right, there could be made a case that these sound bites are either of so low amplitude that the sound cannot be heard or that the label is many fold (that the sound bite can actually be labeled as multiple of the possible categories).