DataProcessingSQL
Know our data
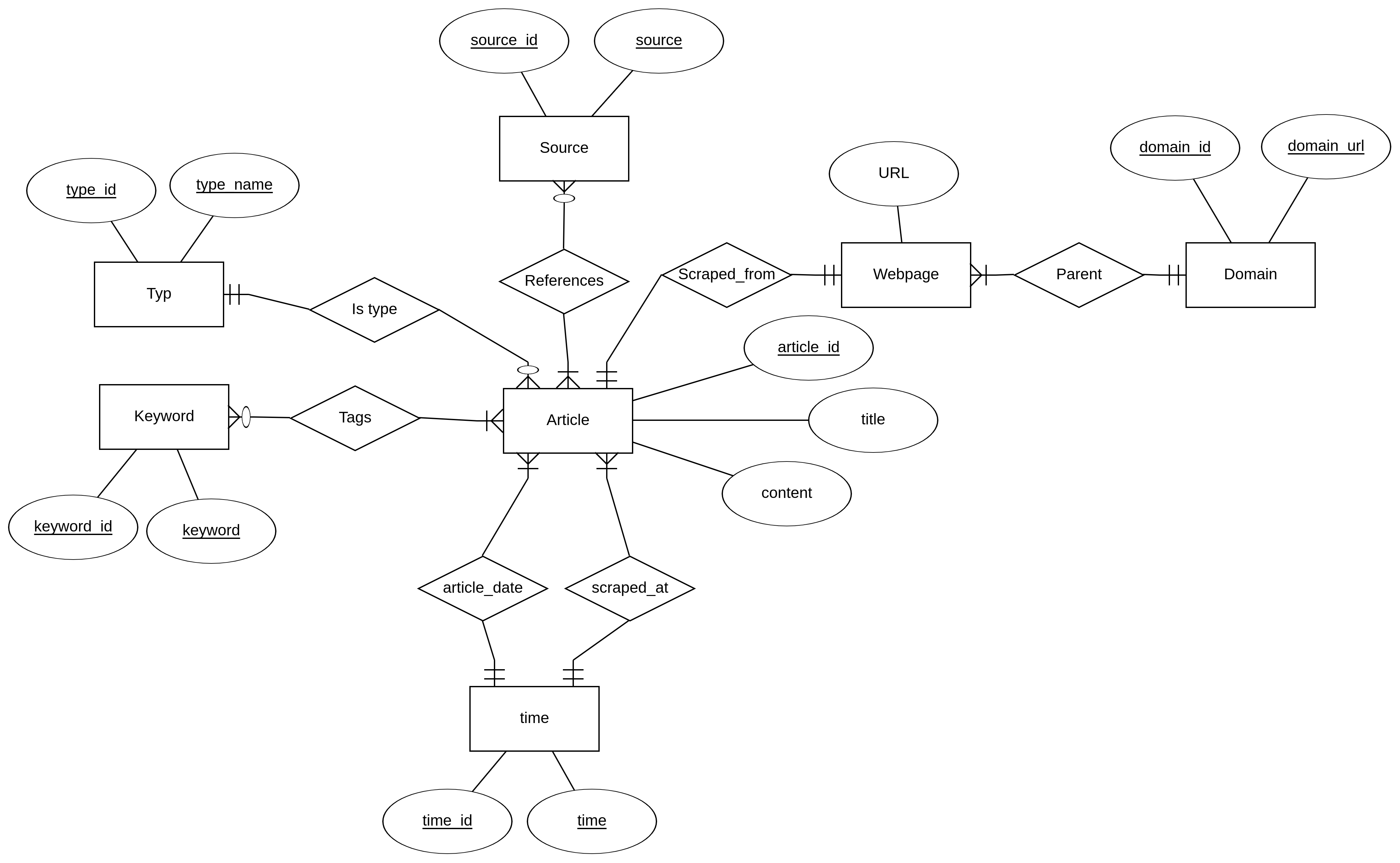
The design of the schema that contains the data from the FakeNews Corpus data set
In our design of the schema, we have tried to reduce various anomalies as much as possible. We started by cramming all the data into a single relation, but we quickly found out that this created a lot of anomalies. Therefore, we iteratively decomposed this relations until we ended up with the design that can be viewed on figure \ref{fig:er-diagram-fakenews-corpus}. By designing our database this way, we have reduced redundancy, update anomalies, and deletion anomalies significant.
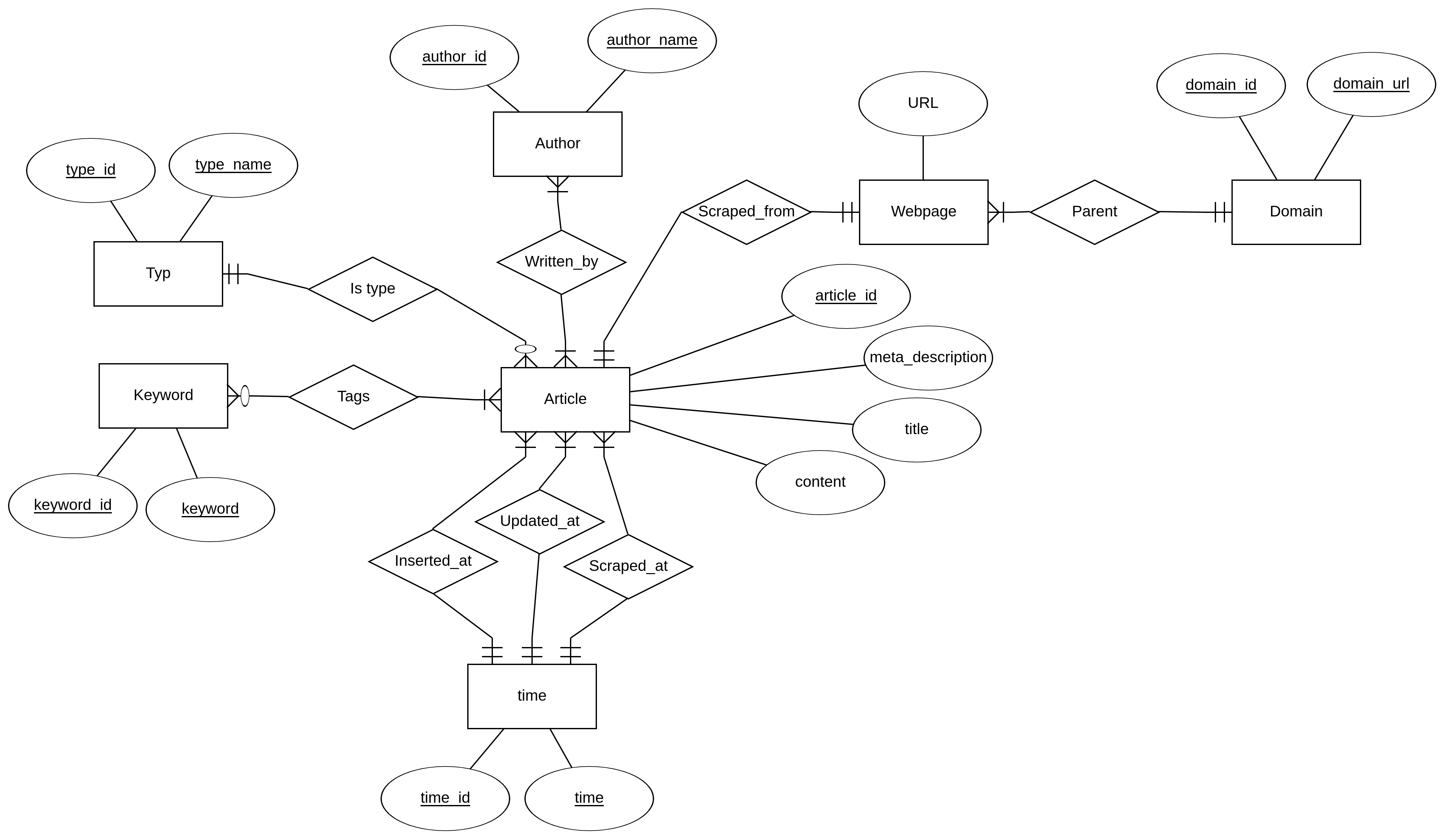
The reason why we have a time relation, is that we found out that there are only 5 different timestamps. Therefore, we could remove many anomalies by making it a separate relation. For all the relationships that are one-to-many or many-to-many, we have likewise separated them into their own relations. This includes the following relations: keyword, typ, author, webpage, and domain.
We have assumed, that no article contains the same content, and no articles contains the same meta_description. We did find out, that some of the articles actually have the same title, so we could reduce anomalies by separating this attribute into its own relation. However, we decided to keep it as an attribute. Since we often use the title, it would make it cumbersome to make a natural join each time we need it.
Inherent problems with the data from the Fakenews Corpus data set during development
We found that some of the data is in the wrong fields, and some of it are not formatted correctly. Furthermore, we also found out that the fields keyword and summary are completely empty for all the articles. For many of the articles, the field called meta_descriptions does not contain anything.
Another problem we found while working with the data set was that we did not understand the difference between meta_keyword and keyword. We assume that meta_keyword contains the keywords of the articles. Likewise, we did not understand the difference between meta_description and summary. Here we assume that meta_description contains a summary of the articles.
Another problem with the data set is that there are two different IDs. The first ID is the unnamed field, which repeats itself after 100000 articles. The second ID, which is called id in the csv file, is quite random. Because of these two problems we create our own article_id instead of using the id’s that were provided.
Properties on the Fakenews Corpus data set
The queries that we have used to get the statistics and visualizations, that can be seen below, can also be found in \hyperref[Appendix A]{Appendix A}.
From this table, one can see that our database contains a lot of articles.
| Basic Statistics | |
|---|---|
| Number of articles: | 999992 |
| Avg. number of keywords per article: | 6.96 |
| Avg. number of words per article: | 271.32 |
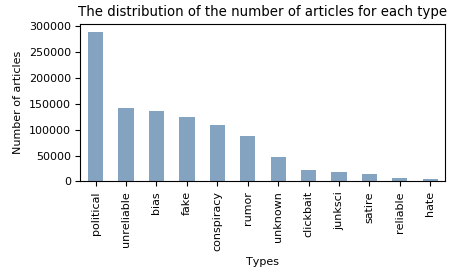
In the figure below, one can see that the database does not contain a lot of reliable articles. It is also possible to observe that the distribution is not uniform. These two properties of the data set can create difficulties when we have to train our model for the predictor.
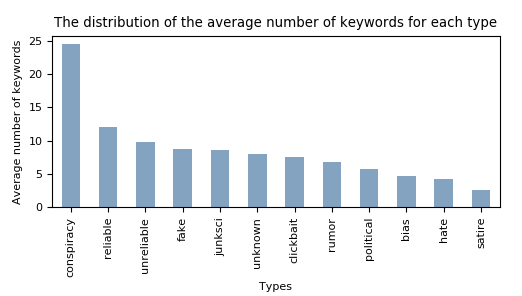
Our initial thought was that clickbait articles would contain a lot of keywords since they could be used to oversell the articles but this is not the case as can be seen in the figure.
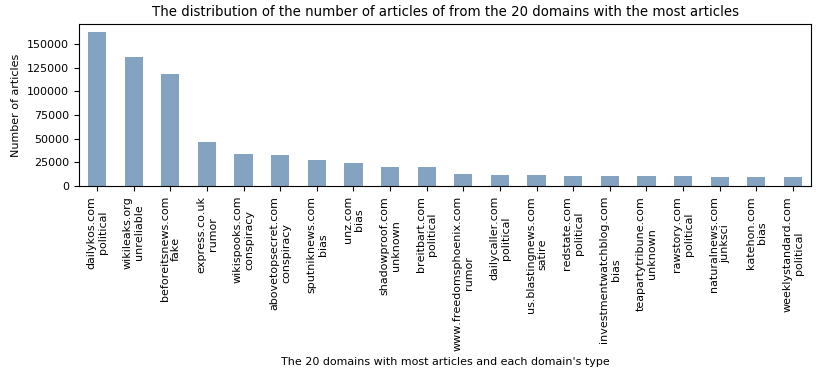
The 20 domains with the most articles scraped from:
From figure below, one can see that approximately 40% of the articles comes from the three domains: dailykos, wikileaks, and beforeitsnews. If these three sites are labeled wrong, all the articles from these three domains are labeled wrong, which will have a huge impact on our predictor.
SELECT count(*),
domain_url,
type_name
FROM fakenewscorpus.article
NATURAL JOIN fakenewscorpus.webpage
NATURAL JOIN fakenewscorpus.domain
NATURAL JOIN fakenewscorpus.typ
GROUP BY domain_url,
type_name
ORDER BY COUNT DESC
LIMIT 20;The average content length of the articles of each type:
Below we can see a figure of the article length (characters in the article) given the type that the article is labeled with. It is clear that the “hate” article type has a far higher average wordcount in relation to the other article types.
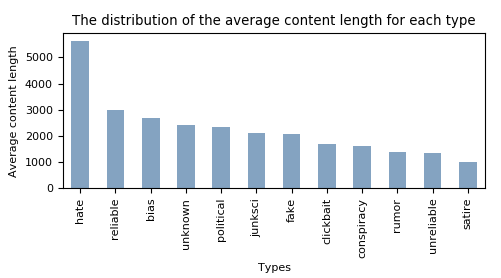
SELECT type_name,
avg(content_length) AS avg_content_length
FROM
(SELECT article_id,
title,
length(content) AS content_length,
type_id
FROM fakenewscorpus.Article) AS tmpTable
NATURAL JOIN fakenewscorpus.typ
GROUP BY type_name
ORDER BY avg_content_length DESC;The average number of words of the articles of each type:
Below we see that the number of words correspont to the length of the article. It is there not beacuse the articles of type hate have far longer words in their articles that they have a longer average article length.
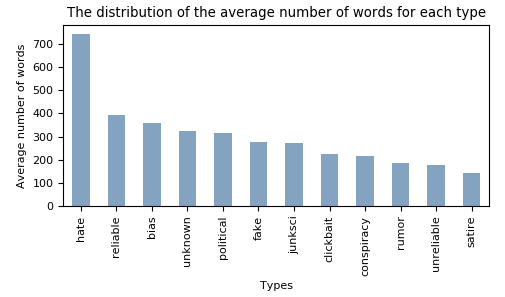
SELECT type_name,
avg(word_count) AS avg_word_count
FROM
(SELECT article_id,
length(replace(content, ' ', '')) AS content_length_no_spaces,
length(content) - length(replace(content, ' ', '')) AS word_count,
type_id
FROM fakenewscorpus.Article) AS tmpTable
NATURAL JOIN fakenewscorpus.typ
GROUP BY type_name
ORDER BY avg_word_count DESC;The average word length of the articles of each type:
This is confirmed by selecting the average wordcount for each of the article types.
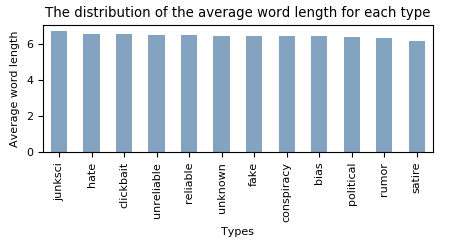
SELECT type_name,
avg(content_length_no_spaces) / avg(word_count) AS avg_word_length
FROM
(SELECT article_id,
length(replace(content, ' ', '')) AS content_length_no_spaces,
length(content) - length(replace(content, ' ', '')) AS word_count,
type_id
FROM fakenewscorpus.Article) AS tmpTable
NATURAL JOIN fakenewscorpus.typ
GROUP BY type_name
ORDER BY avg_word_length DESC;Experiences with scraping from the “Politics and Conflict” section of the Wikinews site
We started with the approach of using all the start urls on the form of:
https://en.wikinews.org/w/index.php?title=Category:Politics_and_conflicts&from=letter where letter is [D-N].
The downside of this was, that not all articles was on their start letter page. This meant that some F articles was on another page, and was thus not included. Furthermore we got some articles from other letters. We solved this by checking for WantedArticles = r"/wiki/[D-N]".
The next approach was to yield the parse() on itself when going to next page and starting on the D page. The spider would thus crawl to nextpage until it reached the letter O.
Extracting the specific information from each article was a bit of a hassle. Some articles' content are structured in tables while over 90% have their content in paragraphs.
Below we have the first parser of the spider.
This spider will run over all of the articles and yield the url to the individual articles and parse them to the parse2 function (line 9). After having scraped all articles for one subpage it will proceed to the next page, if such exists (line 20)
|
|
Below we have the parser for each individual article that is parsed from function parse above.
The parse2 function will yield the title, url, keywords (only applicable to some), date of writting the article, sources used in article
|
|
The design of the schema that contains the data from the Wikinews Fragment data set
We have designed the schema that contains the data from the Wikinews Fragment data set, more or less, like how we designed the schema, that contains the data from the Fakenews Corpus data set. The only differences between the Fakenews Corpus schema design, and this Wikinews Fragment schema design, is that we do not have a meta_description attribute. We do not have an updated_at or inserted_at date, but instead we have a written_at date, and that the articles do not have any authors but they instead have sources. The picture of the E/R diagram can be seen below
Basic properties of the Wikinews Fragment data set
In the table below, one can see that our Wikinews Fragment does not contain a lot of articles. However, since they are all classified as reliable, if we combine these with our Fakenews Corpus data set, we get approximately 50% more reliable articles than was contained in the Fakenews Corpus data set.
From the statistics in the table, we can also observe, that the articles are quite small. We can also see, that the average number of words per article is 176, compared to 271 which was the average number of words per article in the Fakenews Corpus data set.
| Basic Statistics | |
|---|---|
| Number of articles: | 2747 |
| Avg. number of keywords per article: | 9.51 |
| Avg. number of words per article : | 176.89 |
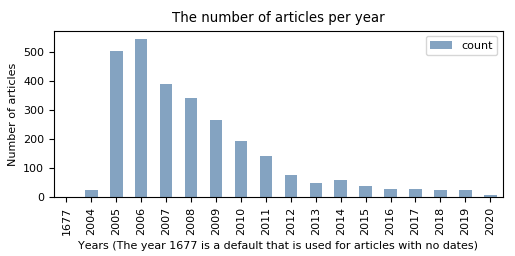
In figure we can observe that distribution of when the articles were published is not uniform. We can see that the vast majority of the articles are from before 2009.
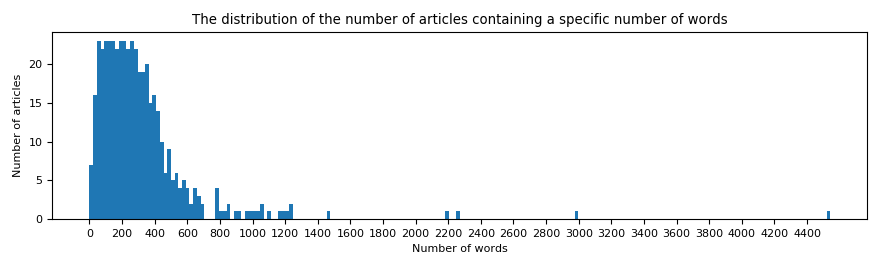
In figure we can see that we could cut the length of the content of the articles to 500 words and get the vast majority of the data. This could be a good idea to reduce the use of memory and computation.
Integration of the Fakenews Corpus data set and Wikinews Fragment data set
The sql command that creates the view can be found at \hyperref[sql-command to create view]{Appendix E}. We have tried to get as much of the meta data integrated in this view as possible.
In the view each article has the following attributes: content, title, type, domain, and url. We could have included scraped_at, but we thought that it is not very useful in regards to our predictor. We decided to not include the information that is represented as many-to-many relationships such as keywords since that would blow up the size of the view.
Our view contains 1002602 articles.
Choosing a dataset
Since our predictor cannot be trained on more than 50k articles, and the Fakenews Corpus dataset contains around 6000 reliable articles, in order to get a balanced training set, we are not able to include the Wikinews Fragment dataset. Furthermore the classification used to determine all wikinews articles as being reliable does not have any merit to back it up. If we had access to better machines, it would not be a problem to use the view described in 1.7 that contains both data sets.
Classification into fake and real
We will classify the articles that are reliable or political as real, and all other articles of the other types as fake. The reasoning behind this, is that we would rather have fake negatives than fake positives. Considering the majority of the article types as being fake, will grant us a better insurance that we do not falsely classify fake content as being real. There is either a clear malicious intent (hate, click-bait, fake), or unintended false, or unjustified content (junk-science, satire, conspiracy, unreliable). Content that is considered in the fakenewscorpus as “on the line” will be classified as fake as well (unknown, bias).
Establish a baseline
Basic models on content
In our baseline model we will use a TF-IDF vectorizer to structure the words and their frequency compared to the general frequency of all the training articles. We utilize 457828 article contents and we use two baseline models: a linear SVC, and a Dummy classifier. By the use of these two models we get the results described in this table.
| Classifier | Liar | Fakenews | Kaggle |
|---|---|---|---|
| LinearSVC | 0.514 | 0.78 | 0.648 |
| Dummy | 0.499 | 0.501 | 0.502 |
Including additional fields
In the beginning we thought it could make sense to use keywords. However, a problem with this is that a lot of the articles in our database do not have any keywords.
It might make sense to use the title of the article as a feature. Although, it is short and we expect that more distinct information is found in the content. However, the title in of itself could be used to determine whether an article is a clickbait.
We decide overall that these features from meta-data would not contribute to the general performance of a model.
Appendices
Appendix A - SQL queries to get the properties of the Fakenews Corpus data set
Number of articles:
SELECT count(*)
FROM fakenewscorpus.article;The average number of keywords for each article:
SELECT Avg(keyword_count) AS avg_keyword_count
FROM
(SELECT article_id,
Count(*) AS keyword_count
FROM fakenewscorpus.tags GROUP BY article_id) AS tmpTable
NATURAL JOIN fakenewscorpus.article;The average number of words for each article:
SELECT avg(word_count) AS avg_word_count
FROM
(SELECT length(content) - length(replace(content, ' ', '')) AS word_count
FROM fakenewscorpus.article) AS tmpTable;Distribution of articles over types:
SELECT count(*),
type_name
FROM fakenewscorpus.article
NATURAL JOIN fakenewscorpus.typ
GROUP BY type_name
ORDER BY COUNT DESC;The average number of keywords of the articles of each type:
SELECT type_name,
Avg(keyword_count) AS avg_keyword_count
FROM (SELECT article_id,
Count(*) AS keyword_count
FROM fakenewscorpus.tags
GROUP BY article_id) AS tmpTable
natural JOIN fakenewscorpus.article
natural JOIN fakenewscorpus.typ
GROUP BY type_name
ORDER BY avg_keyword_count DESC;Appendix D - SQL queries to get the properties of the Wikinews Fragment data set
Number of articles:
SELECT count(*)
FROM wikinewsfragment.article;The distribution of the number of articles over dates:
SELECT count(*),
time
FROM wikinewsfragment.article
INNER JOIN wikinewsfragment.time ON wikinewsfragment.article.written_at_time_id = wikinewsfragment.time.time_id
GROUP BY time
ORDER BY COUNT DESC;The average, minimum, and maximum number of keywords for each article:
SELECT Avg(keyword_count) AS avg_keyword_count,
Min(keyword_count) AS min_keyword_count,
Max(keyword_count) AS max_keyword_count
FROM
(SELECT article_id,
Count(*) AS keyword_count
FROM wikinewsfragment.tags GROUP BY article_id) AS tmpTable
NATURAL JOIN wikinewsfragment.article;The number of distribution of the articles with a specific number of words:
SELECT word_count,
count(*)
FROM
(SELECT length(content) - length(replace(content, ' ', '')) AS word_count
FROM wikinewsfragment.article) AS tmpTable
GROUP BY word_count
ORDER BY word_count;The average, minimum, and maximum number of words for each article:
SELECT avg(word_count) AS avg_word_count,
min(word_count) AS min_word_count,
max(word_count) AS max_word_count
FROM
(SELECT length(content) - length(replace(content, ' ', '')) AS word_count
FROM wikinewsfragment.article) AS tmpTable;Appendix E - Query to create the view that integrates the two data sets
CREATE MATERIALIZED VIEW integrateFakenewsSources AS
(SELECT title,
type_name,
content,
url,
domain_url
FROM wikinewsfragment.article
NATURAL JOIN wikinewsfragment.typ
NATURAL JOIN wikinewsfragment.webpage
NATURAL JOIN wikinewsfragment.domain)
UNION ALL
(SELECT title,
type_name,
content,
url,
domain_url
FROM fakenewscorpus.article
NATURAL JOIN fakenewscorpus.typ
NATURAL JOIN fakenewscorpus.webpage
NATURAL JOIN fakenewscorpus.domain);Made in collaboration with